NICE network
For the definition of this network and concepts of normalizing flow, please refer this nice blog: https://lilianweng.github.io/lil-log/2018/10/13/flow-based-deep-generative-models.html, and the pytorch notebook: https://github.com/GiggleLiu/marburg/blob/master/notebooks/nice.ipynb
using NiLang, NiLang.AD
using LinearAlgebra
using DelimitedFiles
using Plotsinclude the optimizer, you can find it under the Adam.jl file in the examples/ folder.
include(NiLang.project_relative_path("examples", "Adam.jl"))gclip! (generic function with 1 method)Model definition
First, define the single layer transformation and its behavior under GVar - the gradient wrapper.
struct NiceLayer{T}
W1::Matrix{T}
b1::Vector{T}
W2::Matrix{T}
b2::Vector{T}
y1::Vector{T}
y1a::Vector{T}
end
"""Apply a single NICE transformation."""
@i function nice_layer!(x::AbstractVector{T}, layer::NiceLayer{T},
y!::AbstractVector{T}) where T
@routine @invcheckoff begin
i_affine!(layer.y1, layer.W1, layer.b1, x)
@inbounds for i=1:length(layer.y1)
if (layer.y1[i] > 0, ~)
layer.y1a[i] += layer.y1[i]
end
end
end
i_affine!(y!, layer.W2, layer.b2, layer.y1a)
~@routine
# clean up accumulated rounding error, since this memory is reused.
@safe layer.y1 .= zero(T)
endHere, in each layer, we use the information in x to update y!. During computing, we use the y1 and y1a fields of the network as ancilla space, both of them can be uncomputed at the end of the function. However, we need to erase small numbers to make sure the rounding error does not accumulate.
A nice network always transforms inputs reversibly. We update one half of x! a time, so that input and output memory space do not clash.
const NiceNetwork{T} = Vector{NiceLayer{T}}
"""Apply a the whole NICE network."""
@i function nice_network!(x!::AbstractVector{T}, network::NiceNetwork{T}) where T
@invcheckoff for i=1:length(network)
np ← length(x!)
if (i%2==0, ~)
@inbounds nice_layer!(x! |> subarray(np÷2+1:np), network[i], x! |> subarray(1:np÷2))
else
@inbounds nice_layer!(x! |> subarray(1:np÷2), network[i], x! |> subarray(np÷2+1:np))
end
np → length(x!)
end
end
function random_nice_network(nparams::Int, nhidden::Int, nlayer::Int; scale=0.1)
random_nice_network(Float64, nparams, nhidden, nlayer; scale=scale)
end
function random_nice_network(::Type{T}, nparams::Int, nhidden::Int, nlayer::Int; scale=0.1) where T
nin = nparams÷2
scale = T(scale)
y1 = zeros(T, nhidden)
NiceLayer{T}[NiceLayer(randn(T, nhidden, nin)*scale, randn(T, nhidden)*scale,
randn(T, nin, nhidden)*scale, randn(T, nin)*scale, y1, zero(y1)) for _ = 1:nlayer]
endrandom_nice_network (generic function with 2 methods)Parameter management
nparameters(n::NiceLayer) = length(n.W1) + length(n.b1) + length(n.W2) + length(n.b2)
nparameters(n::NiceNetwork) = sum(nparameters, n)
"""collect parameters in the `layer` into a vector `out`."""
function collect_params!(out, layer::NiceLayer)
a, b, c, d = length(layer.W1), length(layer.b1), length(layer.W2), length(layer.b2)
out[1:a] .= vec(layer.W1)
out[a+1:a+b] .= layer.b1
out[a+b+1:a+b+c] .= vec(layer.W2)
out[a+b+c+1:end] .= layer.b2
return out
end
"""dispatch vectorized parameters `out` into the `layer`."""
function dispatch_params!(layer::NiceLayer, out)
a, b, c, d = length(layer.W1), length(layer.b1), length(layer.W2), length(layer.b2)
vec(layer.W1) .= out[1:a]
layer.b1 .= out[a+1:a+b]
vec(layer.W2) .= out[a+b+1:a+b+c]
layer.b2 .= out[a+b+c+1:end]
return layer
end
function collect_params(n::NiceNetwork{T}) where T
out = zeros(T, nparameters(n))
k = 0
for layer in n
np = nparameters(layer)
collect_params!(view(out, k+1:k+np), layer)
k += np
end
return out
end
function dispatch_params!(network::NiceNetwork, out)
k = 0
for layer in network
np = nparameters(layer)
dispatch_params!(layer, view(out, k+1:k+np))
k += np
end
return network
enddispatch_params! (generic function with 2 methods)Loss function
To obtain the log-probability of a data.
@i function logp!(out!::T, x!::AbstractVector{T}, network::NiceNetwork{T}) where T
(~nice_network!)(x!, network)
@invcheckoff for i = 1:length(x!)
@routine begin
xsq ← zero(T)
@inbounds xsq += x![i]^2
end
out! -= 0.5 * xsq
~@routine
end
endThe negative-log-likelihood loss function
@i function nice_nll!(out!::T, cum!::T, xs!::Matrix{T}, network::NiceNetwork{T}) where T
@invcheckoff for i=1:size(xs!, 2)
@inbounds logp!(cum!, xs! |> subarray(:,i), network)
end
out! -= cum!/(@const size(xs!, 2))
endTraining
function train(x_data, model; num_epochs = 800)
num_vars = size(x_data, 1)
params = collect_params(model)
optimizer = Adam(; lr=0.01)
for epoch = 1:num_epochs
loss, a, b, c = nice_nll!(0.0, 0.0, copy(x_data), model)
if epoch % 50 == 1
println("epoch = $epoch, loss = $loss")
display(showmodel(x_data, model))
end
_, _, _, gmodel = (~nice_nll!)(GVar(loss, 1.0), GVar(a), GVar(b), GVar(c))
g = grad.(collect_params(gmodel))
update!(params, grad.(collect_params(gmodel)), optimizer)
dispatch_params!(model, params)
end
return model
end
function showmodel(x_data, model; nsamples=2000)
scatter(x_data[1,1:nsamples], x_data[2,1:nsamples]; xlims=(-5,5), ylims=(-5,5))
zs = randn(2, nsamples)
for i=1:nsamples
nice_network!(view(zs, :, i), model)
end
scatter!(zs[1,:], zs[2,:])
endshowmodel (generic function with 1 method)you can find the training data in examples/ folder
x_data = Matrix(readdlm(NiLang.project_relative_path("examples", "train.dat"))')
import Random; Random.seed!(22)
model = random_nice_network(Float64, size(x_data, 1), 10, 4; scale=0.1)4-element Vector{Main.NiceLayer{Float64}}:
Main.NiceLayer{Float64}([0.10365283655905022; 0.12832890997547838; … ; 0.10237515285351262; 0.04561278390444176;;], [0.011932671083999709, -0.019461834760040552, 0.09841074615805545, -0.049932719417439035, 0.046770637156686626, 0.094738950442398, -0.07072722954885365, -0.14442322991493425, -0.04050736246766045, 0.0161302098597473], [-0.09076531278487276 -0.08893617376065133 … 0.17688969929809442 0.03332683434777908], [-0.05466360224358683], [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
Main.NiceLayer{Float64}([0.04778285245528021; 0.002073152425026603; … ; 0.08114267515467105; 0.03446269262358759;;], [0.015323637584496678, -0.030552214751628316, 0.013764716144273565, 0.3100695796150575, -0.261192567636749, 0.2497349959460083, 0.028594287515553797, 0.027736168629672472, 0.09212377303866616, -0.023160843492401398], [-0.07950664144707173 0.06607646105462771 … -0.06372020403545663 -0.01468114678613847], [-0.05369268305611946], [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
Main.NiceLayer{Float64}([-0.01994222941233885; -0.12354790135192664; … ; 0.0914829134828038; 0.05468284490890261;;], [0.099984884595698, 0.035003360565331286, -0.01215996827091547, -0.012953387260835123, 0.07587204372806554, -0.023394565668740614, -0.0102036220459518, 0.06005046391996989, -0.14314572987011717, 0.13861740098537687], [0.10258920416705185 -0.009778532190417643 … 0.0669491035775922 -0.17052131152319536], [0.03905158369614853], [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
Main.NiceLayer{Float64}([-0.08079652822924399; -0.012018109547847596; … ; -0.0030313328377010503; -0.1035614822693211;;], [0.001980495005703741, -0.21924945243644256, 0.03722989450292816, -0.28291833693177126, 0.135309838967398, -0.021263453632266387, -0.11186250420913675, -0.08763936642038139, 0.06871598760276267, -0.0008703720158541838], [0.04464510169137048 -0.05871256825097563 … 0.13781815631646493 0.08481594857843244], [-0.029644007854268524], [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])Before training, the distribution looks like 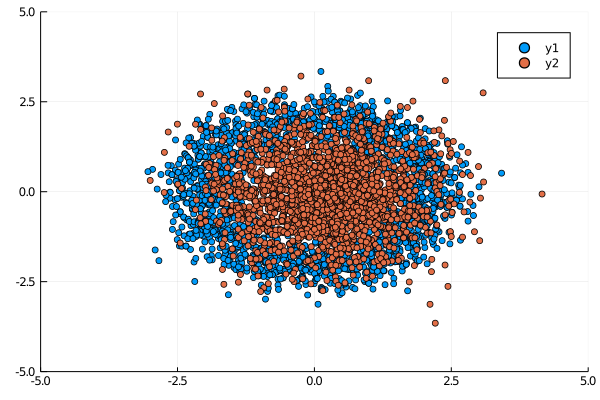
model = train(x_data, model; num_epochs=800)After training, the distribution looks like 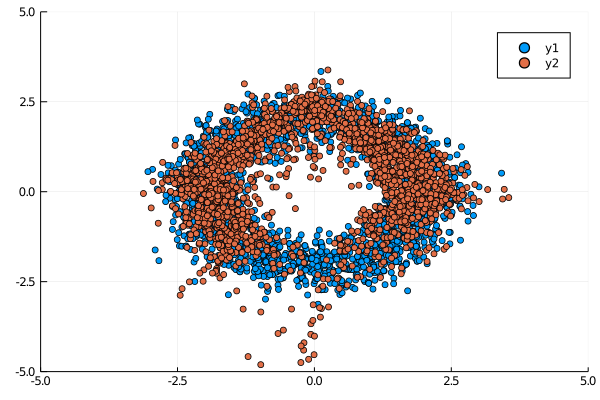
This page was generated using Literate.jl.